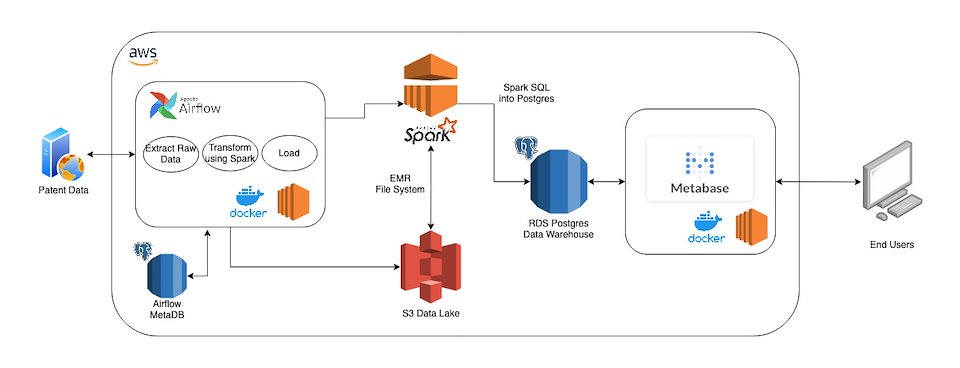
Around A Data Pipeline In 80 Hours
Running predictive machine learning models. Analyzing internal data to improve a product. Telling a data driven story. Those are the sorts of ideas that get a lot of folks excited about the power of data. But a foundation must be in place to make that data accessible. Easy - just build a data pipeline!
Throwing together a couple of python scripts to download data may work for a one time analysis, but how do you architect a data pipeline so that is is repeatable and resilient? How do you make it easy to maintain and debug? How do you quickly deploy it to business users and analysts without sacrificing months of full time work to get it done? Andres Tavio and I decided to take a shot at it.